#Libros blancos
¿Edge Computing, Fog Computing o ambos?
Computación en la nube
¿Qué es la computación en nube?
Una definición simplificada de la computación en nube es la potencia de cálculo proporcionada como un servicio en línea. En función de las necesidades, se puede alquilar a un proveedor de servicios en la nube un hardware (Infrastructure as a Service, IaaS), una plataforma (Platform as a Service, PaaS) o directamente un software preconfigurado (Software as a Service, SaaS). Estas soluciones son especialmente ventajosas en el caso de necesidades de almacenamiento fluctuantes o si se quiere evitar la adquisición de hardware/software propio. Un buen ejemplo son los proveedores de servicios de almacenamiento y gestión de archivos en línea. Por ejemplo, Google Drive es un servicio de este tipo. Aquí, los archivos no se almacenan en dispositivos físicos, sino "en la nube". En las aplicaciones industriales, estos datos, que se presentan de muchas formas, pueden proceder de los sensores del IoT. Se pueden enviar a un servicio en la nube como Microsoft Azure. Para ello, hay que transferir los datos desde los dispositivos físicos sobre el terreno a la nube. Aquí es donde entran en juego el edge computing y el Fog computing.
Visión y ejemplo de edge computing
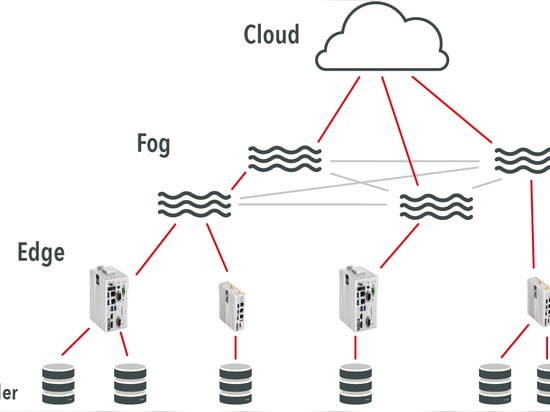
La computación de borde, en contraste con la computación de niebla, tiene lugar directamente en el dispositivo final, es decir, en el mismo borde de la red. Con Edge Computing, los datos de los sensores conectados se recogen, se filtran, se comprimen, se cifran si es necesario y se envían. Las denominadas pasarelas de borde IoT pueden utilizarse para el preprocesamiento en el dispositivo final. Cuando se utilizan pasarelas de borde, a diferencia de las soluciones integradas, la vida útil de los sensores conectados o la duración de la batería pueden ampliarse, ya que los análisis complejos se externalizan. Un ejemplo de uso razonable de la computación de borde son los contadores inteligentes. Los contadores inteligentes son contadores de electricidad inteligentes que producen una gran cantidad de datos tomando medidas a intervalos cortos. Con la ayuda de Edge Computing, en este caso a través de la solución integrada, los datos pueden reducirse antes de que se transporten por la red. Puede encontrar más información sobre Edge Computing en nuestro corto explicativo.
Visión y ejemplo de Fog Computing
La computación en la niebla es una capa de computación entre la nube y el borde. Con la computación de borde, se pueden enviar grandes flujos de datos directamente a la nube. La computación en la niebla, por su parte, puede recibir datos de la capa de borde antes de que lleguen a la nube. Entonces, sólo se almacenan en la nube los datos relevantes. Al mismo tiempo, los datos irrelevantes pueden eliminarse o analizarse en la capa de niebla para el acceso remoto o para informar a los modelos de aprendizaje localizados. Un buen ejemplo de Fog computing sería una aplicación embebida en una línea de producción en la que un sensor de temperatura conectado a una pasarela de borde mide la temperatura cada segundo. Estos datos se enviarían a la nube para controlar los picos de temperatura. Imagine que todas las mediciones de temperatura, cada segundo de un ciclo de medición 24/7, se envían a la nube. Con una capa de niebla, la pasarela de borde enviaría primero los datos a la capa de niebla a través de una red localizada. En función de determinados parámetros, aquí se decide si se envían datos a la nube y cuáles. Esto reduce el tráfico de datos. Para las simples lecturas de temperatura, este ahorro de datos puede parecer insignificante. Pero imagine el impacto si estos flujos de datos constantes se llenaran de información mucho más compleja o de archivos de gran tamaño, como imágenes o vídeos.
Ventajas de la informática de niebla
Una de las ventajas es la eficiencia del tráfico de datos y la reducción de la latencia. La implementación de una capa de niebla reduce los datos que recibe la nube para su aplicación específica integrada. Esto le permite responder directamente a los datos de la capa Fog. Otras ventajas son que se necesita menos espacio de almacenamiento para la aplicación en la nube y que la transferencia de datos es más rápida debido al menor volumen de datos.
Desventajas de la informática de niebla
Está claro que la computación de niebla no puede sustituir a la computación de borde. Sin embargo, la computación de borde puede funcionar sin la computación de niebla. La informática de niebla es un sistema complejo que debe integrarse en una infraestructura existente. Esto supone un gran esfuerzo. Por lo tanto, el Fog Computing no es adecuado para todos los escenarios. Sin embargo, para algunas aplicaciones, las ventajas anteriores pueden ser atractivas si se utiliza una arquitectura de datos directa del borde a la nube.
Diferencias entre Edge Computing y Fog Computing - Funcionalidades
Los términos Fog y Edge Computing se utilizan a menudo de forma redundante. Sin embargo, ahora hay una demarcación bien definida entre las dos soluciones. En consecuencia, Fog Computing es un término genérico para el preprocesamiento de datos en la red local, Edge Computing es una forma especial de preprocesamiento de datos. Un dispositivo Fog conoce todos los dispositivos presentes en el dominio. Durante los análisis, se puede acceder a los otros dispositivos y comunicarse con ellos. Los dispositivos de niebla pueden tomar decisiones basadas en los datos que reciben y almacenar en caché pequeñas cantidades de datos. El Edge, por su parte, realiza tareas como el filtrado y el resumen de datos. Los dispositivos de borde no se conocen entre sí y, por tanto, no interactúan.
Los nodos de la niebla suelen ser dispositivos que ya existen en la red. Se encuentran en un nivel jerárquico adicional entre los dispositivos finales y la nube. La computación de borde, en cambio, tiene lugar directamente en el dispositivo final o incluso en él.
Elegir el hardware y el software adecuados
La idea de la computación en la niebla se basa en el uso de dispositivos que ya están presentes en la red (por ejemplo, routers industriales, gateways, servidores). Esto significa que en este caso no se necesita un hardware especial. Sin embargo, los dispositivos ya existentes deben integrarse en una red Fog con el software adecuado. Este tipo de software ya está disponible en muchos proveedores. En la mayoría de los casos, son los propios proveedores de la nube los que proporcionan soluciones de software para la conexión en red desde el nivel de la niebla hasta la nube respectiva.
La computación de borde, en cambio, se basa principalmente en el hardware. Las funciones de edge computing mencionadas anteriormente se ejecutan en muchos dispositivos finales. Están integrados en los sistemas existentes y los proporciona el fabricante. Si los datos de un dispositivo final sin esta funcionalidad deben ser procesados en el borde, se requiere un hardware adicional, como una pasarela de borde. Los dispositivos tienen una gran variedad de interfaces para conectar diferentes dispositivos finales.
En cuanto al hardware necesario o al tipo de ordenador industrial, una pasarela de borde puede utilizarse fácilmente para el mismo fin que un servidor Fog. La razón es que hay diferencias en la recogida y el procesamiento de datos, pero no en las funciones y capacidades del hardware.